Understanding Timeouts in Ruby (MRI)
- TLDR
- Introduction
- Basics
- Implementation
- Looking into the Source
- Timeout Prerequisites
- Working Examples
- The Typhoeus Case
- Conclusion
0. TLDR
The post is pretty long so I’m gonna summarize the main points:
Timing out a code involves creating a separate thread that halts long CPU tasks + blocked IO via an "interrupt queue" and an optional "unblock function". These things are handled for you if you use standard ruby API directly
If you roll out a C extension and you don't use the interrupt primitives, Ruby's Timeout stdlib won't work.
Typheous didnt work with Timeout because even though the FFI interface is setup to handle the "interrupt queue" checking and "unblock function" setup, the program gets stuck at an external shared library (libcurl) and doesn't go back to the ruby C API level. And by not going back to the ruby C code that's setup up to check the "interrupt queue", timeout doesn't succeed.
For cases like Typhoeus, it's better to just use library's own internal timeout mechanism instead of using Timeout stdlib
1. Introduction
Ruby’s Timeout stdlib is pretty handy for simple use cases when you want to set a time-limit to a method call. However, I recently discovered that it’s not guaranteed to work all the time. No, it’s not the same timeout problem we were having in Ruby 1.8, where the green threads were not properly scheduled and SystemTimer was introduced. We’ve already moved on to native OS threads since 1.9. Let’s look at the following example.
require 'socket'
require 'typhoeus'
server = TCPServer.new 2000
Timeout.timeout(3) { Typhoeus.get("http://localhost:2000") }This code hangs indefinitely instead of raising Timeout::Error after 3 seconds. To understand why it doesnt work for this case, we’re gonna understand why it works for other cases by digging into MRI internals of timeout. The ruby version used in code examples below would be ruby-2.1.0-r39908. Note that other ruby implementations such as JRuby, Rubinius have their own timeout implementations, and I’m only covering MRI here. But before we jump into it, let’s do a quick overview of how CRuby’s Timeout works in high level.
2. Basics
Here’s the basic idea behind timeout: while the code you wrapped inside timeout is running, a second thread is created that sleeps for amount of time you specfied. If the timeout is reached before your code finishes, second thread wakes up and it’ll tell the main thread to stop whatever it’s doing. If your code finishes before the second thread wakes up, the second thread is killed as its function to timeout is no longer needed and your code resumes as if nothing happened.
3. Implementation
So the question is, how does one thread stop another thread’s task? The short answer is Thread#raise
The longer answer is that Thread#raise first adds an exception to the interrupt queue of the target thread. Then at some point in the time, the target thread will check this interrupt queue. When it sees that there’s an exception, it will raise it. By doing so, the thread doesn’t complete its previous operation and thus the timeout is respected.
So essentially, any task inside Timeout::timeout needs to check the interrupt queue periodically so that it’ll know when to stop doing its current instruction. It’s trivial to check this queue when a task is performing a long running CPU task as it can just call a function in between function calls. But when a task is blocked on IO or wait, then it becomes trickier. We shall see in a moment on how this is handled.
To make things clearer, let’s look at the diagram below:
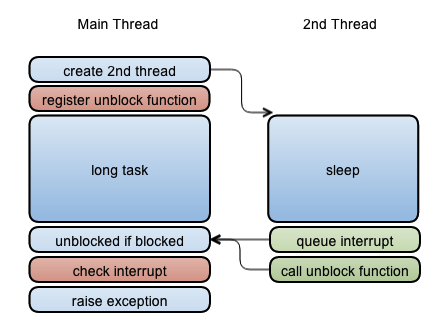
Using our example in the beginning, the Main thread is the one performing the Typhoeus method call, which is labelled as “long task”. Before it performs its task, Main thread will need to register an “unblock function” if it’s doing a blocking IO/wait operation. Timeout::timeout creates a second thread which sleeps for N seconds, and once it wakes up, it calls Thread#raise. This method actually does two things: “queue interrupt”, which adds exception to interrupt queue and “call unblock function”, which calls the unblock function that the Main thread registered if it did setup one. This will unblock the Main thread if it is blocked.
Now if we go back and look at Main thread column, we see that all it needs to do is make sure to check the “interrupt queue” periodically so that it can raise an exception when added by another thread. And if the main thread is blocked, the “unblock function” called by second thread will unblock it, enabling it to check the queue.
4. Looking into the Source
To verify that what we have modeled so far in the diagram above is correct, we can look at the source.
Starting with Thread#raise, we can see that the relevant c function is thread_raise_m. If we inline the functions and only include the most relevant parts, we see that the code below aligns with our Thread#raise explanation.
static VALUE
thread_raise_m(int argc, VALUE *argv, VALUE self)
{
exc = rb_make_exception(argc, argv); // initialize exception
rb_ary_push(th->pending_interrupt_queue, exc); // add exception to "interrupt queue"
RUBY_VM_SET_INTERRUPT(th); // set the "interrupt_flag" to indicate interrupt happened
(th->unblock.func)(th->unblock.arg); // call an unblocking function to unblock a blocked method
return Qnil;
}And for handling Thread#raise, let’s look at the ruby sleep example, a blocking wait call. The code below listing native_sleep and sleep_forever (simplified to include only relevant parts), shows why ruby’s sleep works with Timeout.
static void
native_sleep(rb_thread_t *th, struct timeval *timeout_tv)
{
th->unblock.func = ubf_pthread_cond_signal; // registers the unblock function
native_cond_wait(cond, lock); // blocking function call
}
static void
sleep_forever(rb_thread_t *th, int deadlockable, int spurious_check)
{
native_sleep(th, 0);
RUBY_VM_CHECK_INTS_BLOCKING(th); // check interrupt queue and raise exception
}native_cond_wait blocks the function, and the unblock function ubf_pthread_cond_signal will be called once Thead#raise is executed, allowing native_cond_wait instruction to return immediately, and continue the execution. It then calls RUBY_VM_CHECK_INTS_BLOCKING, which will check the interrupt queue. It sees that there’s an exception and raises it, resulting in ruby’s sleep being interrupted.
5. Timeout Prerequisites
Essentially, for a code inside a Timeout::timeout block to work, it needs to do 2 things. First, if it’s a blocking call, it needs to register an unblock function in th->unblock.func. Second, it needs to check interrupt queue (RUBY_VM_CHECK_INTS_BLOCKING and RUBY_VM_CHECK_INTS macros are used often for these purposes)
Let’s look at some other ruby examples where timeout works, and check if these prerequisites are handled.
6. Working Examples
Net::HTTP (blocking IO)
If we change the example in the beginning by replacing the code block inside the timeout call with Net::HTTP.get(URI.parse("http://localhost:2000/")), the timeout will work. Let’s see if it registers an unblock function and checks the interrupt queue.
Net::HTTP delegates to IO.select(read_array, write_array, error_array, timeout) which is a wrapper around the system call select(2) and it uses a default timeout of 60 seconds. This means that the IO.select call will block until any of the file descriptors specified in read/write/error arrays becomes ready for writing/reading or if it receives an interrupt.
If we look at the source of IO.select, the calltrace looks like this:
rb_f_select
rb_ensure
select_call
select_internal
rb_thread_fd_select
do_select # where the interrupt handling happens
native_fd_select
rb_fd_select # dispatches to select(2) system call
In those list of function calls, if we look at do_select, we’ll see the presence of “unblock function” and “interrupt checking”
BLOCKING_REGION({
result = native_fd_select(n, read, write, except, timeout, th);
if (result < 0) lerrno = errno;
}, ubf_select, th, FALSE);
RUBY_VM_CHECK_INTS_BLOCKING(th);The unblock function ubf_select registered via the BLOCKING_REGION macro, calls ubf_select_each which issues a SIGVTALRM signal to the thread. As a result, blocking operation such as select(2), poll(2), recv(2) return immediately, returning the error code EINTR. Instead of waiting for full 60 seconds for select(2) to finish, it return right away, allowing it to check the interrupt queue via RUBY_VM_CHECK_INTS_BLOCKING.
(1..200000).reduce(:*)
Let’s look at long CPU operations this time around.
The code above multiplies numbers 1 to 200,000 by each other, and the numbers becomes big enough that it’ll eventually use the bignum multiply operation. Here’s the call trace for multiplying bignum
rb_big_mul
bigmul0
bigmul1_normal
If we look at bigmul1_normal, we’ll see that it calls rb_thread_check_ints, which just calls RUBY_VM_CHECK_INTS_BLOCKING. There’s no need to register unblock function here because it’s not blocked on IO/wait. Essentially, there are roughly ~200,000 multiply operations, and after each one is executed, it checks the interrupt queue. That’s why its able to respond to timeouts.
static VALUE
bigmul1_normal(VALUE x, VALUE y)
{
...
rb_thread_check_ints();
return z;
}while(true); end
How about a while loop? If we get the YARV instructions of while(true), we see that it’s basically calling jump repeatedly:
puts RubyVM::InstructionSequence.compile("while(true); end").disasm
== disasm: <RubyVM::InstructionSequence:<compiled>@<compiled>>==========
== catch table
| catch type: break st: 0006 ed: 0009 sp: 0000 cont: 0009
| catch type: next st: 0006 ed: 0009 sp: 0000 cont: 0005
| catch type: redo st: 0006 ed: 0009 sp: 0000 cont: 0006
|------------------------------------------------------------------------
0000 trace 1 ( 1)
0002 jump 6
0004 putnil
0005 pop
0006 jump 6
0008 putnil
0009 leave
Looking at the definition of jump in insns.def, we see that its also checking interrupts via the RUBY_VM_CHECK_INTS. So basically its also compatible with ruby timeout. In fact, if you look other YARV instructions that might result in infinite loops such as throw, leave, branchif, branchunless, they all check the interrupts.
/**
@c jump
@e set PC to (PC + dst).
@j PC を (PC + dst) にする。
*/
DEFINE_INSN
jump
(OFFSET dst)
()
()
{
RUBY_VM_CHECK_INTS(th);
JUMP(dst);
}7. The Typhoeus Case
Having a better understanding of how timeout works, let us go back to our very first example where the Typhoeus get request is hanging. Typhoeus uses Ethon which is an FFI wrapper around libcurl (version 7.19.7 used below). If we ran that example, and attach to the process using gdb, and look at the backtrace, here’s what we get.
(gdb) bt
#0 0x00634422 in __kernel_vsyscall ()
#1 0x00cffac6 in poll () from /lib/tls/i686/cmov/libc.so.6
#2 0x00441729 in Curl_socket_ready (readfd=8, writefd=-1, timeout_ms=1000) at select.c:218
#3 0x0043303f in Transfer (conn=0x8d11c0c) at transfer.c:1948
#4 0x00433e03 in Curl_perform (data=0x8d6633c) at transfer.c:2638
#5 0x00434912 in curl_easy_perform (curl=0x8d6633c) at easy.c:557
#6 0x00e1b63f in ffi_call_SYSV () from /usr/lib/libffi.so.5
#7 0x00e1b46f in ffi_call () from /usr/lib/libffi.so.5
#8 0x00749fe7 in call_blocking_function (data=0xbfb231c0) at Call.c:294
#9 0x002a4ada in call_without_gvl (func=0x749f96 <call_blocking_function>, data1=0xbfb231c0, ubf=0x2a24c0 <ubf_select>, data2=0x876e298, fail_if_interrupted=0) at thread.c:1201
#10 0x002a4be2 in rb_thread_call_without_gvl (func=0x749f96 <call_blocking_function>, data1=0xbfb231c0, ubf=0xffffffff, data2=0x0) at thread.c:1311
#11 0x0074a033 in do_blocking_call (data=0xbfb231c0) at Call.c:303
#12 0x0016825c in rb_rescue2 (b_proc=0x749ffc <do_blocking_call>, data1=3216126400, r_proc=0x74a03e <save_frame_exception>, data2=3216126560) at eval.c:714
#13 0x0074a21e in rbffi_CallFunction (argc=1, argv=0xb77c10c0, function=0x4347f5, fnInfo=0x8b06358) at Call.c:357
#14 0x0074c2a9 in attached_method_invoke (cif=0x763568, mretval=0xbfb232f0, parameters=0xbfb23310, user_data=0x8ad9ba4) at MethodHandle.c:186
#15 0x00e1b76d in ?? () from /usr/lib/libffi.so.5
#16 0x0028770c in call_cfunc_m1 (func=0xb787e138, recv=143284540, argc=1, argv=0xb77c10c0) at vm_insnhelper.c:1320
#17 0x002880fb in vm_call_cfunc_with_frame (th=0x876e298, reg_cfp=0xb7840e50, ci=0x8b97f94) at vm_insnhelper.c:1464
#18 0x002881c8 in vm_call_cfunc (th=0x876e298, reg_cfp=0xb7840e50, ci=0x8b97f94) at vm_insnhelper.c:1554
#19 0x00288a4f in vm_call_method (th=0x876e298, cfp=0xb7840e50, ci=0x8b97f94) at vm_insnhelper.c:1746
#20 0x00289015 in vm_call_general (th=0x876e298, reg_cfp=0xb7840e50, ci=0x8b97f94) at vm_insnhelper.c:1897
#21 0x0028bfcb in vm_exec_core (th=0x876e298, initial=0) at insns.def:1017
#22 0x00298eab in vm_exec (th=0x876e298) at vm.c:1201
#23 0x0029989b in rb_iseq_eval_main (iseqval=144123140) at vm.c:1449
#24 0x001674e5 in ruby_exec_internal (n=0x8972504) at eval.c:250
#25 0x001675fb in ruby_exec_node (n=0x8972504) at eval.c:315
#26 0x001675c5 in ruby_run_node (n=0x8972504) at eval.c:307
#27 0x080487bc in main (argc=2, argv=0xbfb23eb4) at main.c:36
If we look at the function call_without_gvl (9th frame in the backtrace), we see that both an unblock function and interrupt queue checking is in place. So why does timeout not work?
static void *
call_without_gvl(void *(*func)(void *), void *data1,
rb_unblock_function_t *ubf, void *data2, int fail_if_interrupted)
{
...
BLOCKING_REGION({
val = func(data1);
saved_errno = errno;
}, ubf, data2, fail_if_interrupted);
if (!fail_if_interrupted) {
RUBY_VM_CHECK_INTS_BLOCKING(th);
}
...
}The answer lies in the Transfer function (3rd frame in backtrace) in libcurl code below. When Thread#raise is called and poll() function in Curl_socket_ready gets interrupted by SIGVTALRM, error is set to EINTR just like our previous Net::HTTP example. But this time around, it reaches the continue statement, and goes to the beginning of the while condition. Since done is still set to false, it’ll go back to calling Curl_socket_ready function again, never reaching our interrupt checking code.
static CURLcode
Transfer(struct connectdata *conn)
{
...
while(!done) {
switch (Curl_socket_ready(fd_read, fd_write, timeout_ms)) {
case -1:
if(SOCKERRNO == EINTR)
continue;
}
...
}
...
}So even though call_without_gvl was setup to check ruby’s interrupts via RUBY_VM_CHECK_INTS_BLOCKING, it never gets there - the program just loops around libcurl level. It’s not really Ethon library’s fault here, there’s nothing it can really do. We said earlier that making timeout work only requires registering an unblock function and checking interrupts, turns out things are not that simple. If you call an external library and it loops forever and never goes back to the ruby code responsible for checking interrupts as we see in this case, timeout would not succeed.
If we use strace to inspect the stuck program, this is what we’ll see.
clock_gettime(CLOCK_MONOTONIC, {81750, 505754258}) = 0
poll([{fd=8, events=POLLIN|POLLPRI}], 1, 1000) = ? ERESTART_RESTARTBLOCK (To be restarted)
--- SIGVTALRM (Virtual timer expired) @ 0 (0) ---
rt_sigreturn(0xbfbf6de0) = -1 EINTR (Interrupted system call)
clock_gettime(CLOCK_MONOTONIC, {81750, 597709479}) = 0
poll([{fd=8, events=POLLIN|POLLPRI}], 1, 909) = ? ERESTART_RESTARTBLOCK (To be restarted)
--- SIGVTALRM (Virtual timer expired) @ 0 (0) ---
rt_sigreturn(0xbfbf6de0) = -1 EINTR (Interrupted system call)
clock_gettime(CLOCK_MONOTONIC, {81750, 698873103}) = 0
poll([{fd=8, events=POLLIN|POLLPRI}], 1, 807) = ? ERESTART_RESTARTBLOCK (To be restarted)
--- SIGVTALRM (Virtual timer expired) @ 0 (0) ---
rt_sigreturn(0xbfbf6de0) = -1 EINTR (Interrupted system call)
clock_gettime(CLOCK_MONOTONIC, {81750, 799418802}) = 0
poll([{fd=8, events=POLLIN|POLLPRI}], 1, 707) = ? ERESTART_RESTARTBLOCK (To be restarted)
Notice that poll is interrupted by SIGVTALRM and it happens multiple times. We know that Thread#raise only sends SIGVTALRM once, so how come there are others? Apparently, Ruby maintains another thread called the timer_thread. According to this discussion, this is usually used for multithreaded programs to ensure that all threads respond to signal interrupts. If there’s only 1 thread running, this timer_thread would just sleep to reduce power consumption. However, in our case, even though we only 1 have ruby thread running (the 2nd thread is already killed after it executed Thread#raise), the program stuck at libcurl never goes back to the ruby level to tell the timer_thread that it has already handled the Thread#raise signal. So the “timer_thread” will keep issuing the SIGVTALRM, thinking that it’s doing job of letting the thread handle the signal, when in fact its just doing extra useless work.
8. Conclusion
To recap, timeout is not guaranteed to work in all cases. If you’re using the standard ruby API, which periodically checks the interrupt queue for exceptions to raise, it’ll timeout correctly. But if you’re rolling your own C-extension that calls out an infite loop via native sleep or for(;;) {}, timeouts are not gonna just magically work. And for cases like Typhoeus wherein interrupt checking is setup but is never reached, the proper solution is really just to use the library’s own timeout mechanism instead. So for our initial example, replacing the timeout stdlib call with Typhoeus.get("http://localhost:2000", timeout: 3) would have solved the problem. Basically, it’s good idea to test timeout calls first to see if it works. And if a library has its own timeout mechanism, use that instead.